





I. Introduction▲
ElasticSearch est un moteur de recherche open source qui fait beaucoup parler de lui. Et pour cause, il possède un atout majeur : il suffit de quelques minutes à peine pour disposer d'un moteur de recherche clusterisé, automatiquement sauvegardé et répliqué, interrogeable via une API REST et proposant toutes les fonctionnalités d'un moteur de recherche dernière génération.
Malgré une prise en main rapide et une documentation officielle très complète, l'utilisation d'ElasticSearch peut devenir rapidement complexe pour qui n'a jamais utilisé de moteur de recherche. C'est pourquoi nous avons choisi de démarrer une nouvelle série d'articles, dans laquelle nous allons essayer de présenter les notions de base d'ElasticSearch et les fonctionnalités les plus utilisées de ce fantastique outil.
Dans cet article, nous verrons comment installer et configurer ElasticSearch. Nous en profiterons pour introduire les concepts de nœud et de cluster, puis nous effectuerons nos premières indexations de documents et recherches par mots-clés.
II. ElasticSearch : cool, bonsaï, cool !▲
ElasticSearch est un projet open source développé en Java sous licence Apache2. Le projet a été présenté par son créateur, Shay Banon, comme le successeur du framework Compass (un framework de mapping objet/moteur de recherche partageant des similitudes avec Hibernate Search).
La première version a été mise à disposition du public en février 2010. Depuis, le projet tient un rythme soutenu de releases à raison d'une version tous les un ou deux mois.
La version actuelle est 0.19.11, mais ne vous fiez pas à ce numéro ! Le projet est largement mature et est déjà utilisé en production par des organisations importantes telles que la Fondation Mozilla, Foursquare, Yfrog (950 millions de documents indexés), Klout ainsi que la Douane française.
Largement adopté par les utilisateurs et les développeurs, le projet compte de nombreux contributeurs et approche les 3000 followers sur son repository GitHub.
II-A. Au cœur du projet, Apache Lucene▲
ElasticSearch est basé sur l'excellente bibliothèque Apache Lucene. Cette bibliothèque existe depuis de nombreuses années et est au cœur de nombreux moteurs de recherche open source (le plus connu étant Apache SolR). Elle fournit toutes les classes Java nécessaires à l'indexation de documents et à l'exécution des requêtes de recherches.
Lucene étant une bibliothèque de bas niveau, son intégration dans des applications gérant un grand nombre de requêtes concurrentes et/ou un gros volume de données peut s'avérer très complexe. Il n'est d'ailleurs pas rare de rencontrer quelques problèmes de performances, notamment lorsque la taille des index dépasse plusieurs gigaoctets ou lorsque les requêtes de recherche doivent être parallélisées.
ElasticSearch facilite l'utilisation de Lucene en intégrant la bibliothèque dans une application Java modulaire, facilement configurable et capable de fonctionner en cluster. Un raccourci rapide serait de définir ElasticSearch comme un Lucene dans le Cloud, c'est-à-dire un cluster de Lucene.
Ce fonctionnement en cluster, très simple à configurer, permet de répartir automatiquement le volume des données indexées et la charge d'utilisation sur l'ensemble des machines appartenant au cluster. Pour absorber plus de données ou plus de charge, il suffira d'ajouter de nouvelles machines au cluster.
À noter que la prochaine version d'ElasticSearch (0.21) intégrera la version 4 de Lucene et ses nombreuses nouveautés.
II-B. Les fonctionnalités-clés d'ElasticSearch▲
ElasticSearch fournit toutes les fonctionnalités d'un moteur de recherche nouvelle génération : les recherches par mots-clés « à la Google », les recherches par combinaison de critères et de filtres, le tri et la pagination des résultats, la gestion des synonymes, l'extraction de texte à partir de documents binaires, l'analyse et la navigation par facettes… Seules manquent à l'appel les fonctionnalités de correction orthographique automatique (spellchecking) et de groupage de résultats, très utiles, qui ne sont pas encore présentes dans ElasticSearch mais qui seront implémentées dans les prochaines versions du projet.
ElasticSearch dispose en plus de son propre système de plugins. Ce système permet d'ajouter facilement de nouvelles fonctionnalités au moteur de recherche. Parmi les plugins existants, on peut trouver des analyseurs syntaxiques, des interfaces d'administrations ou encore des connecteurs pour indexer différentes sources de données (bases de données relationnelles ou NoSQL, annuaire LDAP, système de fichiers, flux RSS, etc.).
ElasticSearch apporte aussi son lot de fonctionnalités innovantes telles que :
- la percolation, qui permet de préenregistrer des recherches puis d'injecter un document et d'obtenir en retour la liste des recherches correspondant à ce document ;
- les rivières ("Rivers"), qui sont des connecteurs permettant d'indexer un flot continu de documents issus de sources de données variées.
Ces deux fonctionnalités feront l'objet d'un futur article.
Enfin, ElasticSearch dispose d'une API RESTREpresentational State Transfert très complète permettant d'utiliser le moteur de recherche avec de simples requêtes HTTP/JSON.
III. Installer ElasticSearch▲
L'unique prérequis à l'installation d'ElasticSearch est la présence de Java 6 sur la machine destinée à héberger le moteur de recherche.
Pour vérifier si Java 6 est installé, il suffit d'exécuter la commande suivante dans un shell *nix ou une invite de commande Windows :
$ java -version
java version "1.6.0_25"
Java(TM) SE Runtime Environment (build 1.6.0_25-b06)ElasticSearch est distribué sous la forme d'archive zip/tar.gz ou de package .deb à l'adresse http://www.elasticsearch.org/download/.
Une fois l'archive téléchargée, il suffit de la décompresser pour installer ElasticSearch :
$ unzip elasticsearch-0.19.11.zip
Archive: elasticsearch-0.19.11.zip
creating: elasticsearch-0.19.11/
creating: elasticsearch-0.19.11/bin/
creating: elasticsearch-0.19.11/config/
inflating: elasticsearch-0.19.11/bin/elasticsearch.bat
...À ce stade, le répertoire d'installation comprend les répertoires suivants :
- bin, qui contient le script de lancement elasticsearch et le script d'installation de plugins (respectivement elasticsearch.bat et plugin.bat pour Windows) ;
- config, qui contient les fichiers de configuration d'ElasticSearch (elasticsearch.yml) et celui des logs (logging.yml). Nous reviendrons sur ces deux fichiers dans un instant ;
- lib, qui contient certaines bibliothèques utilisées par ElasticSearch.
L'installation d'ElasticSearch est désormais terminée, nous allons pouvoir démarrer ElasticSearch.
Pour cela, il faut exécuter le script elasticsearch (ou elasticsearch.bat sous Windows) :
$ cd elasticsearch-0.19.11/
$ ./bin/elasticsearchÀ noter qu'ElasticSearch peut aussi être installé en tant que service du système d'exploitation en suivant la procédure suivante.
Au lancement, ElasticSearch va créer de nouveaux répertoires :
- data, destiné à contenir les données indexées ;
- logs, qui contient les fichiers de journalisation ;
- work, qui contient des fichiers temporaires nécessaires au fonctionnement du moteur de recherche.
Ce second répertoire va nous être utile pour vérifier le bon lancement d'ElasticSearch. Il suffit de regarder le contenu du principal fichier de log elasticsearch.log dont voici un exemple :
$ tail -f logs/elasticsearch.log
[2012-10-30 15:36:48,100][INFO ][node ] [Elsie-Dee] {0.19.11}[11660]: initializing ...
[2012-10-30 15:36:48,104][INFO ][plugins ] [Elsie-Dee] loaded [], sites []
[2012-10-30 15:36:49,708][INFO ][node ] [Elsie-Dee] {0.19.11}[11660]: initialized
[2012-10-30 15:36:49,708][INFO ][node ] [Elsie-Dee] {0.19.11}[11660]: starting ...
[2012-10-30 15:36:49,784][INFO ][transport ] [Elsie-Dee] bound_address {inet[/0:0:0:0:0:0:0:0:9300]}, publish_address {inet[/192.168.1.17:9300]}
[2012-10-30 15:36:52,835][INFO ][cluster.service ] [Elsie-Dee] new_master [Elsie-Dee][pt99cavSTGuyiDies_6oqw][inet[/192.168.1.17:9300]], reason: zen-disco-join (elected_as_master)
[2012-10-30 15:36:52,875][INFO ][discovery ] [Elsie-Dee] elasticsearch/pt99cavSTGuyiDies_6oqw
[2012-10-30 15:36:52,904][INFO ][http ] [Elsie-Dee] bound_address {inet[/0:0:0:0:0:0:0:0:9200]}, publish_address {inet[/192.168.1.17:9200]}
[2012-10-30 15:36:52,904][INFO ][node ] [Elsie-Dee] {0.19.11}[11660]: startedLa dernière ligne du fichier confirme qu'ElasticSearch est bien démarré (started) et indique son numéro de version (0.19.11) ainsi que le PID du processus (11660).
Une seconde façon de vérifier qu'ElasticSearch s'est correctement lancé consiste à ouvrir l'URL http://localhost:9200/ dans un navigateur Web. En effet, ElasticSearch écoute par défaut sur le port 9200 pour répondre aux éventuelles requêtes HTTP REST qui lui sont faites.
La réponse du serveur confirme le bon fonctionnement d'ElasticSearch et rappelle le numéro de la version installée :
{
"ok": true,
"status": 200,
"name": "Elsie-Dee",
"version": {
"number": "0.19.11",
"snapshot_build": false
},
"tagline": "You Know, for Search"
}Et voilà, nous venons d'installer et de démarrer un premier nœud ElasticSearch !
IV. Introduction au cluster ElasticSearch▲
IV-A. Qu'est-ce qu'un cluster ElasticSearch ?▲
Un cluster ElasticSearch est composé de plusieurs nœuds qui communiquent entre eux. Chaque nœud (node en anglais) correspond à une instance d'ElasticSearch en cours d'exécution, et peut être ajouté ou retiré du cluster même lorsque ce dernier est en train de fonctionner.
En général, il n'existe qu'un nœud par machine (physique ou virtuelle) mais il est tout à fait possible d'installer plusieurs nœuds sur une même machine, notamment pour des besoins de tests ou de montée de version. Dans ce cas et afin d'éviter les collisions, chaque nœud ElasticSearch écoutera automatiquement sur des ports différents : 9200 pour le premier, 9201 pour le second, 9202 pour le troisième, etc.
Au sein d'un cluster, chaque nœud est identifié par un nom unique. S'il n'est pas configuré, le nœud s'attribue automatiquement un nom de super héros parmi une liste plutôt bien fournie.
Ainsi, dans notre exemple le nœud a automatiquement pris le nom « Elsie-Dee »: 2012-10-30 15:36:52,904INFOnode Elsie-Dee {0.19.11}11660: started.
Afin d'éviter que le nom d'un nœud ne change à chaque démarrage, il suffit de configurer la propriété node.name dans le fichier de configuration config/elasticsearch.yml :
node.name: "noeud-0"Au prochain démarrage, notre nœud s'appellera « nœud-0 ».
Un cluster ElasticSearch est identifié de façon unique par un nom. L'appartenance à un cluster est configurée au niveau de chacun des nœuds, dans la propriété cluster.name du fichier de configuration. Par défaut, cette propriété n'est pas renseignée et le nom de cluster est tout simplement « elasticsearch ».
Une bonne pratique consiste à configurer un nom de cluster qui reflète la plateforme (test, intégration, production, etc.) et la version d'ElasticSearch (ce qui peut être pratique pour les futures montées de version) :
cluster.name: "test-0.19.11"Lorsqu'un nœud démarre, il va chercher à rejoindre le cluster de nom cluster.name. Pour cela, il interroge le réseau à la recherche d'autres nœuds en cours d'exécution et vérifie si ces nœuds appartiennent au même cluster que lui. Si d'autres nœuds sont identifiés, le nœud va rejoindre le cluster. Lorsqu'aucun cluster n'est trouvé, le nœud va en créer un pour lui-même en se déclarant comme nœud maitre, dont le rôle est de coordonner certaines opérations au sein du cluster.
L'étape d'identification des clusters et des nœuds est appelée ''Discovery'' (découverte en français) et peut s'effectuer de différentes manières.
IV-B. Découverte en Multicast▲
La configuration par défaut utilise le ''Multicast'' pour l'identification des autres nœuds. Dans ce mode, le nœud en cours de démarrage envoie une requête multicast (en utilisant le port 54328 et l'adresse de groupe 224.2.2.4) sur le réseau, et seuls les nœuds ayant le même nom de cluster lui répondront. Le nœud pourra ensuite rejoindre le cluster.
Ce mode de découverte est très pratique, car il permet de démarrer rapidement un cluster ElasticSearch, mais dans certains cas il est préférable de le désactiver pour éviter que n'importe quel nœud rejoigne le cluster par erreur.
La désactivation du Multicast s'effectue dans le fichier de configuration de chaque nœud :
discovery.zen.ping.multicast.enabled: falseIV-C. Découverte en Unicast▲
La configuration Unicast est utile lorsque le Multicast n'est pas disponible ou lorsqu'il est désactivé. Ce mode nécessite de configurer chaque nœud du cluster avec les adresses et numéros (ou plage) de ports des autres nœuds du cluster, de la façon suivante :
discovery.zen.ping.unicast.hosts: ["host1", "host2:9300", "host3[9300-9399]"]À noter qu'il n'est pas nécessaire qu'un nœud connaisse la totalité des autres nœuds du cluster. Il lui suffit de pouvoir se connecter à un seul autre nœud du cluster pour pouvoir rejoindre ce dernier. La configuration Unicast est conseillée pour les clusters utilisés en production.
IV-D. Découverte EC2▲
Ce dernier mode de découverte permet à des nœuds ElasticSearch de fonctionner correctement sur la plateforme d'Amazon Elastic Compute Cloud (Amazon EC2).
IV-E. Communication entre nœuds▲
Les nœuds d'un cluster ElasticSearch utilisent le framework JBoss Netty pour communiquer entre eux. La communication s'effectue par défaut sur le port 9300 et les messages sont composés d'objets Java sérialisés. Pour cette raison, il est fortement conseillé que tous les nœuds d'un même cluster fonctionnent avec une même version du projet.
Au sein d'un cluster, les nœuds se pingent à intervalles réguliers (par défaut toutes les trois secondes). Si un nœud met trop de temps à répondre ou qu'il ne répond tout simplement pas, il sera exclu du cluster par les autres nœuds. Ce cas peut arriver sur un réseau peu performant ou lorsqu'une coupure réseau survient.
Par défaut, chaque nœud du cluster est capable de réaliser toutes les opérations de recherches et d'indexation de documents, de maintenance du cluster ou de réponse aux requêtes HTTP REST effectuées par les clients. Si besoin, les options de configuration http.enabled (active/désacte le support HTTP REST) et node.data (active/désactive le stockage de données indexées) permettent de spécifier le comportement d'un nœud. Plusieurs protocoles peuvent être utilisés pour communiquer avec les nœuds d'un cluster ElasticSearch: Apache Thrift, ZeroMQ, memcached… Ces protocoles peuvent être utilisés à la place ou en plus de l'API REST HTTP déjà disponible.
Maintenant que le fonctionnement d'un cluster ElasticSearch est un peu plus clair, nous pouvons ajouter un nouveau nœud à notre cluster.
IV-F. Ajout d'un nœud au cluster (avec une configuration Multicast)▲
Le nœud « nœud-0 » précédemment installé est en cours d'exécution. Nous pouvons dupliquer son répertoire de configuration puis supprimer ses répertoires data, work et logs :
$ cp -R elasticsearch-0.19.11/ elasticsearch-0.19.11_bis/
$ rm -rf elasticsearch-0.19.11_bis/data/
$ rm -rf elasticsearch-0.19.11_bis/work/
$ rm -rf elasticsearch-0.19.11_bis/logs/Ensuite, il suffit d'éditer le fichier de configuration et indiquer un autre second nom de nœud nœud-1 :
$ vi elasticsearch-0.19.11_bis/config/elasticsearch.yml
node.name : noeud-1Puis démarrer ce second nœud :
$ cd elasticsearch-0.19.11_bis/
$ ./bin/elasticsearch -fLe fichier de log du nœud-1 confirme bien que le nœud maitre nœud-0 a été identifié :
[INFO ][cluster.service] [noeud-1] detected_master [noeud-0][VPfFZ-1lSY20-AgYrr-jCg][inet[/192.168.1.17:9300]], added {[noeud-0][VPfFZ-1lSY20-AgYrr-jCg][inet[/192.168.1.17:9300]],}, reason: zen-disco-receive(from master [[noeud-0][VPfFZ-1lSY20-AgYrr-jCg][inet[/192.168.1.17:9300]]])Et le fichier de log du nœud-0 confirme l'ajout du nouveau nœud nœud-1 au cluster :
[INFO ][cluster.service] [noeud-0] added {[noeud-1][gURACdMrRSWQfS-Y97Z-pQ][inet[/192.168.1.17:9301]],}, reason: zen-disco-receive(join from node[[noeud-1][gURACdMrRSWQfS-Y97Z-pQ][inet[/192.168.1.17:9301]]])Ce premier cluster ElasticSearch composé de deux nœuds nous sera utile pour mieux appréhender l'indexation de documents avec l'API REST.
IV-G. Installer le plugin ElasticSearch-Head▲
Le plugin ElasticSearch-Head fournit une interface d'administration pour ElasticSearch. Très simple à utiliser, ce plugin permet de consulter la liste des documents indexés dans ElasticSearch, d'effectuer des recherches ou encore d'avoir une représentation graphique de l'état d'un cluster.
L'installation d'un plugin doit être réalisée lorsque le nœud est arrêté. L'API REST dispose d'une commande pour arrêter tous les nœuds d'un cluster :
$ curl -XPOST 'http://localhost:9200/_shutdown'Une fois le nœud arrêté, nous pouvons installer le plugin avec la commande suivante :
$ cd elasticsearch-0.19.11/
$ ./bin/plugin -install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/downloads/mobz/elasticsearch-head/elasticsearch-head-0.19.11.zip...
Trying https://github.com/mobz/elasticsearch-head/zipball/v0.19.11...
Trying https://github.com/mobz/elasticsearch-head/zipball/master...
Downloading .................................DONE
Identified as a _site plugin, moving to _site structure ...
Installed headLe plugin est désormais installé. Nous pouvons alors redémarrer le premier nœud nœud-0 :
$ cd elasticsearch-0.19.11/
$ ./bin/elasticsearch -fPuis le second nœud nœud-1 :
$ cd elasticsearch-0.19.11_bis/
$ ./bin/elasticsearch -fEt enfin, ouvrir l'URL http://localhost:9200/_plugin/head/ dans un navigateur. L'interface du plugin présente bien les deux nœuds du cluster (le nœud master est surligné en orange) :

V. Indexer et rechercher avec ElasticSearch▲
V-A. Vue générale de l'API REST▲
ElasticSearch propose une API REST permettant de réaliser tous types d'opérations. Cette API utilise le format JSON pour les requêtes et les réponses et supporte les principales méthodes HTTP (GET, DELETE, PUT et POST).
Elle est utilisée de la façon suivante :
http://host:port/[index]/[type]/[_action|id]Avec
- index : nom de l'index sur lequel porte l'opération ;
- type : nom du type de document ;
- _action : nom de l'action à effectuer ;
- id : identifiant du document.
V-B. Indexation de documents▲
Voici un exemple d'indexation d'un document de type formation dans un index nommé zenika avec l'API REST :
$ curl -XPUT 'http://localhost:9200/zenika/formation/1' -d '{
"titre": "Formation ElasticSearch",
"sous-titre": "Savoir utiliser et configurer ElasticSearch, le moteur de recherche seconde génération",
"formateurs": [
{
"prenom": "Tanguy",
"nom": "Leroux"
}
],
"jours": 3,
"url": "http://www.zenika.com/formation_elasticsearch.html",
"sessions": [
{
"ville": "Paris",
"dates": [
"20/02/2013",
"29/05/2013"
]
},
{
"ville": "Lyon",
"dates": [
"18/03/2013",
"17/06/2013"
]
}
]
}'La réponse renvoyée par ElasticSearch nous indique que l'indexation s'est bien passée (ok est à true) et nous rappelle l'index, le type et l'identifiant du document indexé :
{
"ok": "true",
"_index": "zenika",
"_type": "formation",
"_id": "1",
"_version": 1
}Le triplet index/type/id correspond aux coordonnées du document, qui permettent de le retrouver parmi tous les documents indexés dans le moteur de recherche.
Un rafraîchissement de la page du plugin ElasticSearch-Head va nous montrer comment l'index zenika a été automatiquement réparti sur nos deux nœuds :
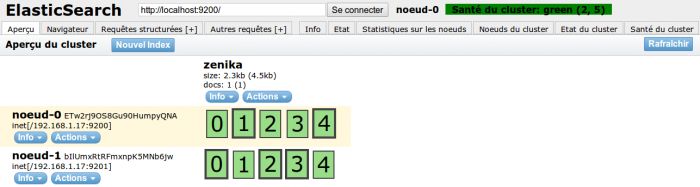
L'onglet Browser (« Navigateur ») du plugin est très pratique pour consulter la liste des documents indexés :
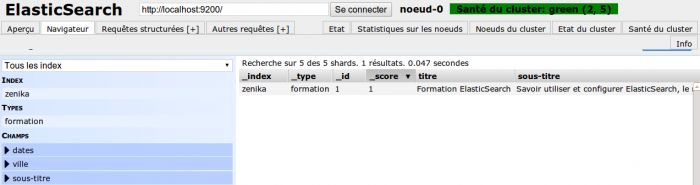
V-C. Rechercher des documents▲
Lorsque les coordonnées d'un document sont connues, il est très facile de le retrouver avec l'API REST. Il suffit d'effectuer une requête GET :
$ curl -XGET 'http://localhost:9200/zenika/formation/1'Et ElasticSearch nous renvoie le document :
{
"_id": "1",
"_index": "zenika",
"_source": {
…
},
"_type": "formation",
"_version": 1,
"exists": true
}Mais la plupart du temps, les coordonnées du document ne sont pas connues. Il nous faut donc retrouver le document avec l'aide de quelques mots-clés.
L'API REST dispose d'un raccourci très pratique pour cela, dans lequel les mots-clés sont passés dans le paramètre q (pour « query ») de l'URL :
$ curl -XGET 'http://localhost:9200/zenika/formation/_search?q=elasticsearch'ElasticSearch nous renverra alors une liste de documents correspondants aux résultats de la recherche :
{
"_shards": {
"failed": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "1",
"_index": "zenika",
"_score": 0.057534903,
"_source": {
...
},
"_type": "formation"
}
],
"max_score": 0.057534903,
"total": 1
},
"timed_out": false,
"took": 11
}Il est aussi possible de rechercher un mot-clé dans un champ précis du document indexé :
$ curl -XGET 'http://localhost:9200/zenika/formation/_search?q=jours:3'Ou encore, retrouver un document à partir d'un fragment de mot-clé :
$ curl -XGET 'http://localhost:9200/zenika/formation/_search?q=tang*'Mais le moteur de recherche est capable de retrouver un document même si le mot-clé n'est pas identique à celui indexé et si aucun index ni type n'est connu :
$ curl -XGET 'http://localhost:9200/_search?q=genration~'VI. Conclusion▲
Mais comment ElasticSearch arrive-t-il à retrouver un tel document ?
Eh bien grâce aux index, aux types de documents et aux mappings, qui feront l'objet de notre prochain article !
VII. Remerciements▲
Cet article a été publié avec l'aimable autorisation de Tanguy Leroux. L'article original (Premiers pas avec ElasticSearch (Partie 1)) peut être vu sur le blog/site de Zenika.
Nous tenons à remercier Claude Leloup pour sa relecture orthographique attentive de cet article et Keulkeul pour la mise au gabarit.