




I. Introduction▲
Un petit rappel des rôles des composants d'un ELK :
- Elasticsearch : moteur d'indexation et de recherche. Conçu pour être facilement scalable horizontalement ;
- Logstash : outil de pipeline de récupération de données opérant des transformations et poussant le résultat dans l'outil de persistance configuré. Un nombre important de connecteurs est disponible permettant de s'interfacer facilement avec les outils du marché ;
- Kibana : IHM de visualisation interagissant avec Elasticsearch pour mettre en forme les données via des graphiques, histogrammes, cartes géographiques, etc.
Remarque : tous ces composants sont libres et gratuits. Des images Docker existent pour chacun d'eux.
L'intégration d'une stack ELK avec Docker n'est pas triviale et plusieurs solutions sont disponibles. Nous allons en voir deux aujourd'hui :
II. Installation d'un ELK▲
Montons un ELK dans un premier temps. L'ensemble de ses composants sont disponibles sous forme d'images docker dans le docker hub, à savoir :
- Elasticsearch version 2.1.1 ;
- Logstash version 2.1.1.-1 ;
- Kibana version 4.3.1.
Voici un fichier docker-compose.yml permettant de démarrer les conteneurs :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
elasticsearch:
image: elasticsearch:2.1.1
volumes:
- /srv/elasticsearch/data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
logstash:
image: logstash:2.1.1
environment:
TZ: Europe/Paris
expose:
- "12201"
ports:
- "12201:12201"
- "12201:12201/udp"
volumes:
- ./conf:/conf
links:
- elasticsearch:elasticsearch
command: logstash -f /conf/gelf.conf
kibana:
image: kibana:4.3
links:
- elasticsearch:elasticsearch
ports:
- "5601:5601"
Description de ce fichier :
-
l'image elasticsearch en version 2.1.1 est utilisée
- le dossier /srv/elasticsearch/data de l'hôte est mappé sur le dossier /usr/share/elasticsearch/data du conteneur,
- le port 9200 est exposé et est mappé tel quel sur l'hôte ;
-
l'image logstash en version 2.1.1 est référencée
- le dossier conf/ du dossier courant est mappé sur le dossier /conf du conteneur,
- le port 12201 en TCP et UDP est mappé sur l'hôte,
- le conteneur elasticsearch est lié à logstash, ce qui permet d'associer un nom d'hôte elasticsearch avec l'IP réelle du conteneur elasticsearch ;
- l'image kibana est démarrée en version 4.3, le port 5601 est mappé sur l'hôte et ce conteneur sera également lié à elasticsearch.
Le fichier de configuration de logstash référence le connecteur d'entrée gelf en écoutant sur le port 12201 et pousse sur notre elasticsearch :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
input {
gelf {
type => docker
port => 12201
}
}
output {
elasticsearch {
hosts => elasticsearch
}
}
Voici l'arborescence des fichiers :
├── docker-compose.yml
└── conf/
└── gelf.confPour tout lancer, il suffit de lancer la commande suivante dans le dossier contenant le fichier docker-compose.yml :
docker-compose upDocker va récupérer les images puis démarrer les conteneurs. Il faut attendre quelques secondes le bon démarrage puis une trace de la forme suivante indique le démarrage de Kibana. Elasticsearch est un peu plus long à démarrer.
kibana_1 | {"type":"log","@timestamp":"2016-02-01T09:33:07+00:00","tags":["listening","info"],"pid":1,"message":"Server running at http://0.0.0.0:5601"}
Il est également possible de vérifier le démarrage d'Elasticsearch en se connectant sur « http://ip_machine:5601/status ».
Il faut ensuite ouvrir son navigateur sur « http://ip_machine:5601 » et l'interface suivante s'affiche :
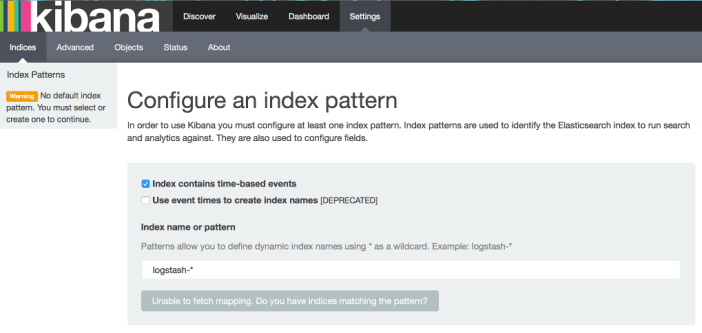
Sur cet écran, Kibana propose de sélectionner l'index elasticsearch, mais il n'est pas possible de valider le formulaire ; en effet, aucune donnée et donc aucun index n'a été créé dans ES, Kibana a besoin d'analyser les index pour afficher les informations.
Nous allons voir comment peupler les données.
III. Driver gelf de Docker▲
Docker offre nativement depuis la version 1.8.2 un driver de logs au format GELF (Graylog Extended Log Format). Celui-ci permet de pousser les logs produits par un conteneur vers un serveur graylog ou logstash. Ce dernier sera utilisé.
Pour utiliser ce driver, voici les options de lancement d'un conteneur à ajouter :
--log-driver=gelf --log-opt gelf-address=udp://ip_machine:12201Lançons donc un conteneur qui produit des traces sur stdout :
docker run --log-driver=gelf --log-opt gelf-address=udp://192.168.10.2:12201 debian bash -c 'seq 1 10'
Remarque : 192.168.10.2 est l'IP de la machine exécutant le démon docker.
Une suite de nombres de 1 à 10 s'affiche en console.
Vérifions que ces informations sont bien accessibles dans Kibana : en rechargeant la page de sélection d'index, il est maintenant possible de valider le formulaire :
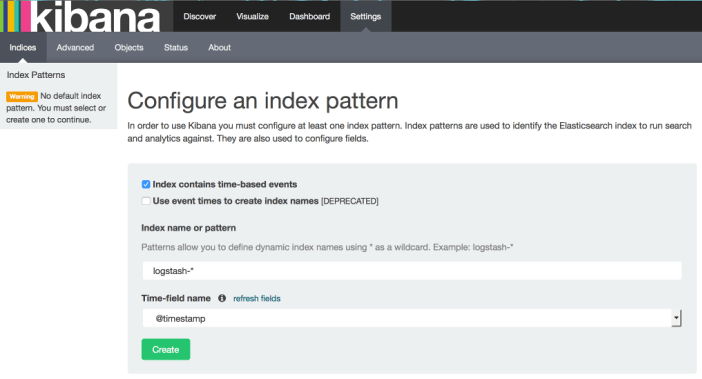
L'onglet settings présente ici les différents attributs disponibles et leur type.

Puis en allant sur l'onglet discover, nous retrouvons les 10 traces produites précédemment :
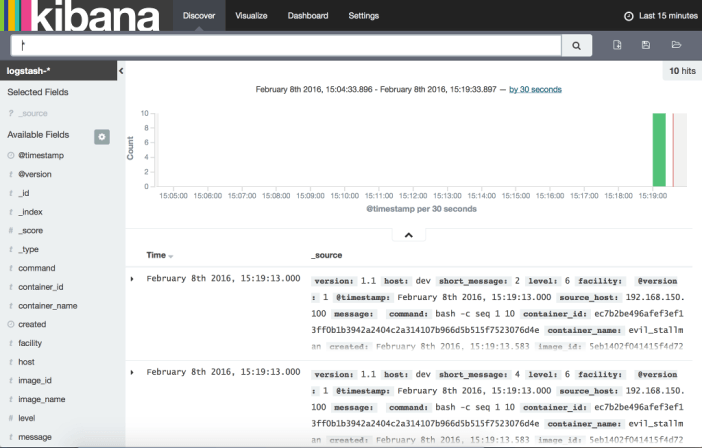
L'interface présente plusieurs onglets :
- settings : enregistre les index et leurs caractéristiques ;
- discover : affichage rapide des informations et test des requêtes ;
- visualize : création/édition des différents diagrammes graphiques ;
- dashboard : synthétise les recherches et les agrège dans un tableau de bord.
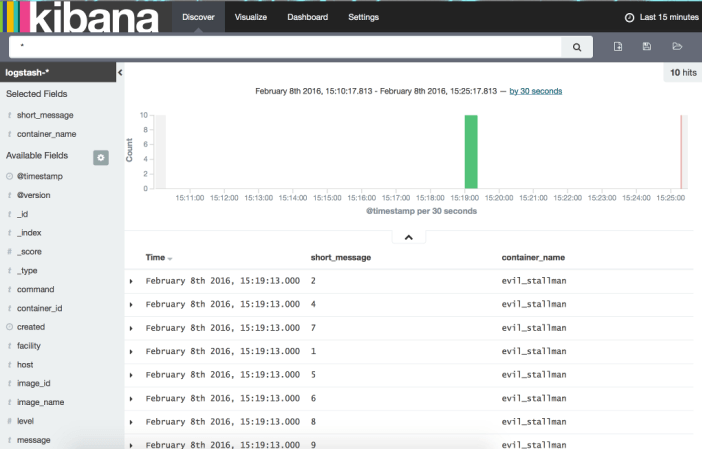
Il est possible de raffiner l'affichage en ne sélectionnant que les colonnes intéressantes. Voici une description de quelques colonnes :
|
Attribut |
Usage |
|---|---|
|
short_message |
Trace de log |
|
created |
Date de création de la trace |
|
command |
Commande lancée dans le conteneur |
|
host |
Nom d'hôte de la machine docker |
|
image_name |
Nom de l'image |
|
container_name |
Nom de l'instance |
Voyons ce que ça donne avec les colonnes filtrées :
Nous avons vu comment monter un ELK et indiquer à un conteneur où produire ses traces, les avantages et inconvénients sont les suivants :
|
Avantages |
Inconvénients |
|---|---|
|
|
Pour pallier le dernier point, il est possible de paramétrer le démon docker pour qu'il utilise directement ce driver pour tous les conteneurs et éviter ainsi la configuration à chaque instanciation d'image.
Sous centos 7, éditer le fichier /usr/lib/systemd/system/docker.service et mettre à jour la ligne commençant par ExecStart :
ExecStart=/usr/bin/docker daemon --log-driver=gelf --log-opt gelf-address=udp://ip_machine:12201 -H fd://
Attention toutefois avec cette configuration : il est préférable que le logstash soit une machine différente de ce démon docker afin de pouvoir logger le démarrage de docker en cas de besoin.
IV. Utilisation du conteneur Logspout▲
Logspout est un conteneur lisant les logs bruts produits par l'ensemble des conteneurs s'exécutant sur l'instance de démon docker en écoutant sur la socket /var/run/docker.sock et les envoie sur un appender logstash.
Par défaut, l'image Logspout officielle ne possède pas de driver logstash, mais il existe un driver libre et disponible. Nous allons l'ajouter dans notre image.
Pour commencer, il faut récupérer l'image logspout :
docker pull gliderlabs/logspout:masterSe placer dans un nouveau dossier, et créer un fichier modules.go contenant :
2.
3.
4.
5.
6.
package main
import (
_ "github.com/looplab/logspout-logstash"
_ "github.com/gliderlabs/logspout/transports/udp"
)
Ce fichier source écrit en golang sera automatiquement inclus dans l'image que nous produisons.
L'image gliderlabs/logspout définie à l'aide de l'instruction ONBUILDlogspout les opérations à réaliser lorsqu'une image fille sera construite. Ici, un script va alors récupérer tout le nécessaire pour recompiler l'outil logspout en intégrant ce nouveau driver (ce n'est pas très « user friendly », mais c'est exécuté une seule fois).
Puis, ajouter la ligne suivante dans un fichier Dockerfile :
FROM gliderlabs/logspout:masterDésormais, nous avons deux fichiers dans le dossier courant :
Voici l'arborescence des fichiers :
├── Dockerfile
└── modules.goConstruisons notre image :
docker build -t zenika/logspout .Note : s'il y a un proxy d'entreprise à passer, pensez à ajouter les options --build-arg http_proxy=http://user:motdepasse@monproxy.com:3128 --build-arg https_proxy=https://user:motdepasse@monproxy.com:3128
Il est maintenant nécessaire de reconfigurer logstash pour ajouter un nouveau type d'input. Modifions le fichier gelf.conf de la première partie :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
input {
gelf {
type => docker
port => 12201
}
udp {
port => 5000
codec => json
}
}
output {
elasticsearch {
hosts => elasticsearch
}
}
Modifions également le fichier docker-compose.yml pour ajouter :
- la variable d'environnement LOGSPOUT: ignore au conteneur logstash : cela indique que les traces émises par ce conteneur ne doivent pas être transmises. Cela va éviter d'avoir une boucle infinie ;
- le mapping du port 5000 :
...
logstash:
image: logstash:2.1.1
environment:
TZ: Europe/Paris
LOGSPOUT: ignore
expose:
- "12201"
- "5000"
ports:
- "5000:5000/udp"
- "12201:12201"
- "12201:12201/udp"
volumes:
- ./conf:/conf
links:
- elasticsearch:elasticsearch
command: logstash -f /conf/gelf.conf
...Relançons ELK :
docker-compose upNous pouvons enfin instancier notre nouvelle image :
docker run --name="logspout" \
--volume=/var/run/docker.sock:/tmp/docker.sock \
zenika/logspout \
logstash://192.168.10.2:5000Description des arguments :
- --volume : mapping du fichier /var/run/docker.sock de la machine hôte vers le fichier /tmp/docker.sock du conteneur. Il s'agit de la socket docker sur laquelle circulent tous les événements docker ;
- logstash://192.168.10.2:5000 : adresse vers l'instance logstash écoutant.
Relançons le conteneur qui produisait des logs :
docker run debian bash -c 'seq 1 10'Connectons-nous à Kibana pour retrouver ces traces. Il est important de noter que le nom des attributs change entre cette solution et la précédente, il faut indiquer à Kibana de réanalyser l'index. Allez dans l'onglet settings, puis sur l'icône orange de rechargement.
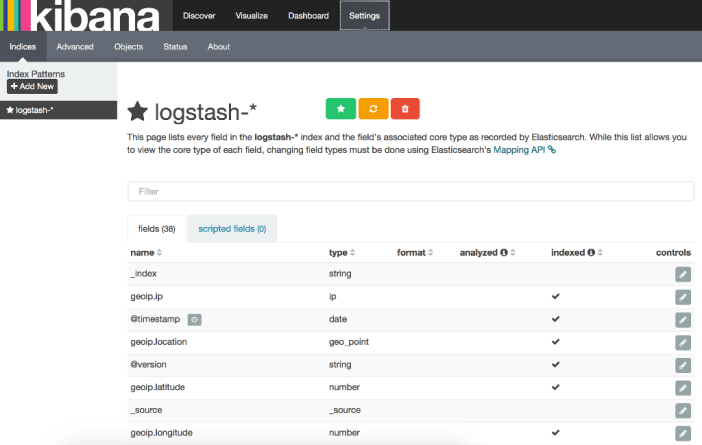
Puis retournons dans l'onglet Discover et comme pour la première partie, sélectionnons les colonnes les plus intéressantes :
|
Attribut |
Usage |
|---|---|
|
message |
Trace de log |
|
time |
Heure de création du message |
|
docker.image |
Nom de l'image |
|
host |
Ip de l'hôte docker |
|
docker.name |
Nom de l'instance de conteneur |
|
docker.id |
Id de l'instance de conteneur |
Voyons maintenant l'affichage des logs :
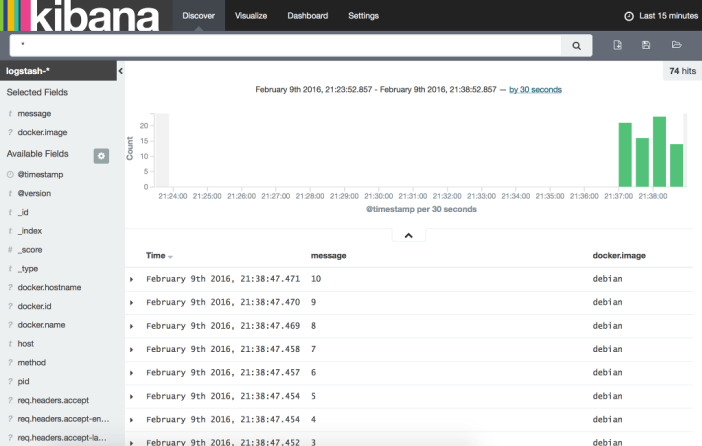
Pour cette seconde solution, les avantages et inconvénients sont les suivants :
|
Avantages |
Inconvénients |
|---|---|
|
|
V. Conclusion▲
Nous avons vu deux possibilités pour pousser les traces des conteneurs dans un ElasticSearch. Leur mise en œuvre présente chacune des avantages et inconvénients qu'il faut prendre en compte pour le choix final. Ma préférence va pour le conteneur logspout qui est le moins intrusif.
Il existe également plusieurs autres solutions avec syslog, fluentd ou filebeat.
Le lecteur attentif aura remarqué que certaines lignes de log ne sont pas ordonnées correctement, cela fera l'objet d'un prochain article pour résoudre ce « petit » détail.
Maintenant, yapluka(c) créer des « dashboard » avec des beaux graphiques & co.
Tous nos remerciements à Vincent Vialé pour la mise en forme et à Claude Leloup pour la relecture orthographique.