





I. Introduction▲
On ne présente plus Hibernate tellement il est utilisé de nos jours dans les applications Java. Cependant, le fonctionnement exact de la session reste souvent un mystère pour beaucoup d'utilisateurs.
Il est donc utile de voir des exemples de manipulation de la session, et notamment dans un domaine cher à nos clients, les traitements de masse et l'optimisation de performance.
Cet article présente donc différentes façons de traiter des quantités importantes de données et détaille les caractéristiques de chaque solution.
I-A. Exemple▲
Le scénario utilisé ici sera l'insertion de 10 000 enregistrements en une seule transaction. Pour cela, nous utilisons un module de réservation de transport qui utilise le modèle de données suivant : les différents moyens de transport (avion, train) sont déjà présents en base, et l'ajout de données concernera la table réservation et ses tables associées : Facture (one-to-one), Voyageur (one-to-many) et Transport (many-to-many).
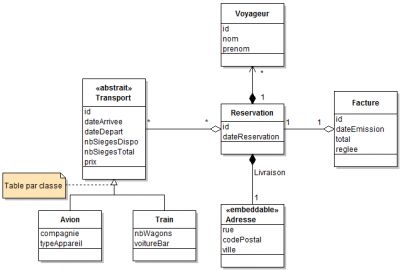
II. Scénarii, mesures et optimisations▲
II-A. Utilisation standard▲
Voici les temps mesurés lorsqu'on persiste traditionnellement les objets en base avec session.persist() (JPA : entityManager.persist()), avec 64 Mo de mémoire.
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
Nominal Test - Flush Default |
1 |
15 021,604 |
15 021,604 |
15 021,604 |
15 021,604 |
|
Flush Session |
1 |
13 584,654 |
13 584,654 |
13 584,654 |
13 584,654 |
|
Ajouter 10000 réservations |
1 |
1 423,281 |
1 423,281 |
1 423,281 |
1 423,281 |
|
Ajouter 1 réservation |
10000 |
0,133 |
0,106 |
22,735 |
1 326,291 |
Total : 15 021 ms
On remarque que le flush est effectué une seule fois, à la fin du traitement et qu'il prend plus de 12 secondes à lui tout seul ! Cette méthode présente un inconvénient majeur. L'utilisation de la mémoire n'est pas maîtrisée et on risque une OutOfMemoryError. En effet, toutes les entités sont conservées dans le cache de niveau 1 d'Hibernate (la session) et ne sont supprimées qu'à la fin de la session.
Avec 48 Mo de mémoire, le même test échoue avec un beau OutOfMemoryError.
II-B. Impact du nombre d'entités en session▲
J'en profite pour faire un aparté sur le fonctionnement d'Hibernate. En interne, pour optimiser ses traitements (flush, regroupement d'instruction, etc.), Hibernate analyse régulièrement sa session et plus il y a d'objets dans la session, plus l'utilisation interne d'Hibernate est coûteuse.
Le test suivant montre les temps d'exécution du code précédant, alors que plusieurs milliers d'entités sont déjà présentes dans la session.
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
Nominal Test - Flush Default |
1 |
25 792,565 |
25 792,565 |
25 792,565 |
25 792,565 |
|
Pre-load objects in session |
1 |
68,448 |
68,448 |
68,448 |
68,448 |
|
Ajouter 10000 réservations |
1 |
1 525,327 |
1 525,327 |
1 525,327 |
1 525,327 |
|
Flush Session |
1 |
23 893,634 |
23 893,634 |
23 893,634 |
23 893,634 |
|
Ajouter 1 réservation |
10000 |
0,126 |
0,104 |
18,338 |
1 263,967 |
Total : 25 724 ms (25 792ms - 68ms)
Dans ce cas, le même code met 66% de temps en plus pour s'exécuter ! Cependant, la valeur n'est pas représentative du fait de l'interférence avec les autres facteurs du test et notamment la mémoire.
II-C. Vidage manuel de la session▲
La méthode la plus simple pour remédier à ces problèmes est d'effectuer après chaque insertion un flush session.flush() et un nettoyage de la session session.clear().
Attention, le nettoyage de la session n'est possible que si aucun objet déjà présent en session n'est utilisé dans la suite du traitement. Pour ce genre de problème, il est possible d'utiliser session.evict() pour détacher un objet précis de la session. Voici les nouvelles mesures :
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
Nominal Test - Flush Default |
1 |
9 777,319 |
9 777,319 |
9 777,319 |
9 777,319 |
|
Ajouter 10000 réservations |
1 |
9 776,878 |
9 776,878 |
9 776,878 |
9 776,878 |
|
Ajouter 1 réservation |
10000 |
0,126 |
0,113 |
5,443 |
1 262,092 |
|
Clear Flush Session |
10000 |
0,840 |
0,723 |
163,181 |
8 404,844 |
|
Flush Session |
10000 |
0,805 |
0,697 |
163,140 |
8 053,038 |
Total : 9 777 ms
On observe que le temps de flush et le temps d'insertion unitaire ont fortement diminué. Pour autant, il est possible d'optimiser encore le traitement en faisant des flush moins réguliers, par exemple toutes les 250 opérations unitaires, ce qui nous donne cette fois :
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
Nominal Test - Flush Default |
1 |
8 904,851 |
8 904,851 |
8 904,851 |
8 904,851 |
|
Ajouter 10000 réservations |
1 |
8 904,113 |
8 904,113 |
8 904,113 |
8 904,113 |
|
Ajouter 1 réservation |
10000 |
0,118 |
0,105 |
9,580 |
1 184,427 |
|
Clear Flush Session |
40 |
190,863 |
178,202 |
341,430 |
7 634,537 |
|
Flush Session |
40 |
190,746 |
178,100 |
341,319 |
7 629,834 |
Total : 8 904 ms
On obtient donc un traitement de 8,9 s, soit un gain d'environ 40% par rapport au traitement initial.
II-D. Gestion personnalisée du flush▲
Une autre façon d'optimiser le traitement est d'intervenir sur le FlushMode d'Hibernate.
Par défaut Hibernate flush de façon automatique, au moment qui lui semble opportun pour assurer le bon déroulement du traitement.
Il est possible de changer ce comportement par défaut :
- on peut désactiver le flush automatique et demander que le flush ne s'effectue qu'au commit de la transaction. Pour cela on indique à la session d'utiliser le mode de flush (FlushMode.COMMIT et en JPA FlushModeType.COMMIT) ;
- une autre solution est de désactiver complètement le flush automatique et d'indiquer à Hibernate que le flush sera effectué de façon manuelle, uniquement sur demande (FlushMode.MANUAL, pas d'équivalence en JPA).
Ces deux modes de flush optimisent les traitements en intervenant sur le fonctionnement interne d'Hibernate, car celui-ci ne vérifie plus l'état des objets en session pour savoir s'ils doivent être flushés ou non en fonction du type de requête traitée.
Attention, en changeant le mode de flush, vos modifications en cours ne sont pas persistées en base automatiquement, donc toutes les requêtes effectuées ramènent les valeurs en base. Il faut donc appeler le flush avant de lire des données en cours de modifications.
Avec le flush mode en MANUAL, on obtient les résultats suivants :
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
FlushMode Manual -Flush Default |
1 |
14 810,387 |
14 810,387 |
14 810,387 |
14 810,387 |
|
Flush Session |
1 |
13 376,280 |
13 376,280 |
13 376,280 |
13 376,280 |
|
Ajouter 10000 réservations |
1 |
1 414,282 |
1 414,282 |
1 414,282 |
1 414,282 |
|
Ajouter 1 réservation |
10000 |
0,129 |
0,105 |
23,002 |
1 288,071 |
Total : 14 810 ms
Les résultats montrent très peu de différences, mais ceci est dû au traitement effectué. Dans notre traitement, il n'y a pas de lecture en base, opération qui demande à Hibernate de vérifier l'état de ses objets en session pour flusher si nécessaire. Les gains ne sont pas visibles dans ce test, mais existent réellement dans d'autres situations.
II-E. Session sans états▲
Hibernate propose également un type de session particulier, appelé session sans état (@@StatelessSession@) qui permet de manipuler les entités sans les rattacher à la session.
Ce type de session agit simplement comme une interface directe entre vos objets et votre base de données. Toutes les opérations effectuées (lecture, écriture) sont directement traitées et il n'est plus question de cache de niveau 1 et de problème mémoire.
Si ce type de session est rapide, il faut savoir qu'il y a des limitations à son utilisation. Premièrement, les objets chargés n'étant pas rattachés à la session, le mécanisme de chargement paresseux (lazy-loading) n'existe pas et ce n'est pas si mal quand on sait que c'est souvent une source de mauvaises performances dans ce type de traitement.
Le plus gros inconvénient de cette session est qu'elle ne gère pas les relations de type*ToMany lors de l'insertion de données. Il faut donc passer par une requête en SQL natif pour insérer des nouveaux enregistrements dans ces cas précis.
Note, pour les utilisateurs de JPA, la session sans état ne fait pas partie de la norme, il faudra appeler directement le code Hibernate.
Une fois cette présentation terminée, voyons les temps obtenus avec la session sans état :
|
Measurement Point |
# |
Average |
Min |
Max |
Total |
|---|---|---|---|---|---|
|
Stateless Session |
1 |
8 214,875 |
8 214,875 |
8 214,875 |
8 214,875 |
|
Ajouter 10000 réservations |
1 |
8 214,194 |
8 214,194 |
8 214,194 |
8 214,194 |
|
Ajouter 1 réservation |
10000 |
0,806 |
0,686 |
26,316 |
8 057,380 |
Total : 8 214 ms
Les temps mesurés sont légèrement en dessous des meilleurs temps obtenus lors de l'utilisation de la session « classique », mais il faut dans notre cas passer par l'écriture de requêtes en SQL natif. Je dirai que l'utilisation de la session sans état est fortement conseillée si vous ne faites que de la lecture. Pour les traitements avec des insertions, cela dépend de la complexité de votre modèle de données et de votre besoin.
III. Schéma récapitulatif▲
Le schéma suivant récapitule les différents temps obtenus en fonction du scénario utilisé et de la mémoire définie au niveau de la JVM.
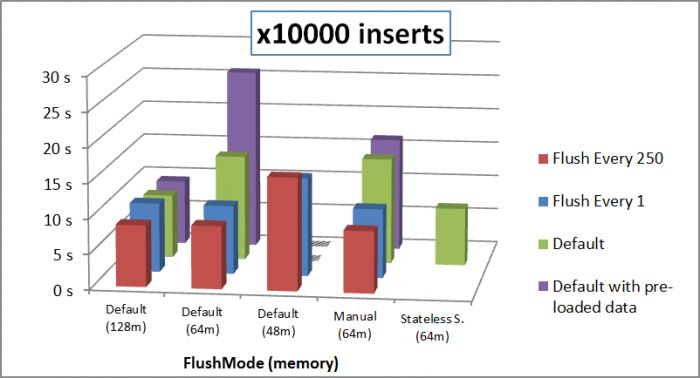
On remarque qu'avec beaucoup de mémoire, on obtient des temps très similaires dans nos tests et qu'avec 48 Mo de mémoire, l'utilisation standard de la session ne permet pas d'aller au bout du test, à cause d'un OutOfMemoryError.
IV. Conclusion▲
S'il y a une chose à retenir de cet article, c'est que dans les problématiques de traitement de masse, il est impératif de maîtriser l'utilisation de la mémoire en passant par une gestion manuelle de la session.
Si on voulait aller plus loin, il y aurait beaucoup d'autres paramètres sur lesquels on pourrait agir pour optimiser les performances.
Il y a bien sûr le cache de niveau 2 et cache de requête, mais aussi les modes de récupération de données (FetchMode ou FetchType en JPA), le traitement par batch, les récupérations de données en mode lecture seule (voir LockMode), l'utilisation des références en JPA (EntityManager.getReference()), l'utilisation de DTO (DataTransfertObject), etc.
Malgré tous ces facteurs à prendre en compte, le plus important est de comprendre comment vous utilisez la session et quelles sont les requêtes que vous générez (attention au lazy-loading). J'espère que cet article vous aura permis d'en apprendre un peu plus sur le fonctionnement de la session et sur les impacts sur les performances de votre application.
V. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société ZenikaZenika, le billet original peut être trouvé sur le blog de ZenikaBlog de Zenika.
Nous tenons à remercier _Max_ pour sa relecture attentive de cet article et Mickael Baron pour la mise au gabarit du billet original.